

(last updated: 2019-11-10 @ 11:15 EST / 2019-11-10 @ 16:15 UTC )
You may have heard, or read, that you should not mix VARCHAR and NVARCHAR datatypes, especially when one of them is a JOIN or WHERE predicate / condition, as doing so will invalidate indexes. While it is always best to have all datatypes be the same for a particular operation (comparison, concatenation, etc), the actual impact of mixing these two types is a bit more nuanced than most people are aware of.
To start with, we need to consider that internally, SQL Server needs the datatypes on both sides of a comparison (or concatenation) to be the same. If you have a mismatch of types and do not explicitly convert one type to the other so that they are the same, then SQL Server will handle this itself. This is called an implicit conversion and is handled by the appropriately named internal function, CONVERT_IMPLICIT() ("internal" meaning you can’t call it, but it will show up in execution plans).
Which datatype will convert to the other is determined by Data Type Precedence. Since N[VAR]CHAR has a higher precedence than [VAR]CHAR, the [VAR]CHAR value will be converted to N[VAR]CHAR. Having the conversions go in this direction makes sense as it should never lead to any data loss since Unicode should be able to map all characters from all 8-bit code pages.
Since we know that [VAR]CHAR will convert to N[VAR]CHAR, then "accidentally" using a [VAR]CHAR value to compare against an N[VAR]CHAR column shouldn’t prevent using an index on that column since the data in that column (and hence in that index) is already "correct" for that operation.
But, on the other hand, "accidentally" using an N[VAR]CHAR value to compare against a [VAR]CHAR column should be expected to have some difficulties since the indexed values are not "correct" for that operation. And, while this scenario is where we start to see issues related to the datatype mismatch, the overall impact on performance depends entirely on the type of Collation being used (as we shall see in just a moment).
There are two types of Collations in SQL Server: SQL Server Collations and Windows Collations:
- SQL Server Collations (names starting with
SQL_) are older Collations that were the only ones available prior to SQL Server 2000. These Collations use simplistic sort orders, and do not handle the great variety of linguistic rules defined by Unicode. They use string-sort (instead of word-sort), cannot do character expansions, etc. In fact, they do not have any Unicode rules defined at all, soN[VAR]CHARdata in these Collations will actually use OS-level Collation rules. - Windows Collations (names not starting with
SQL_) were introduced in SQL Server 2000. These Collations not only have the Unicode rules defined, but they also apply those same linguistic rules to[VAR]CHARdata. This allows 8-bit character types to do word-sort (instead of string-sort), character expansions, etc. While this does come at a slight cost to performance, it also allows for consistency of behavior. And, it's this consistency that helps out greatly when there's a mismatch of datatypes (as we will see in a moment).
While the SQL Server Collations have not been officially deprecated, they mainly exist for backwards compatibility and it is highly recommended that newer Windows Collations should be used unless there's a pressing need to use a SQL Server Collation. Unfortunately, the default Collation for new installations (at least on Operating Systems using "US English" as the language), is a SQL Server Collation — SQL_Latin1_General_CP1_CI_AS — and it is this default that's likely the root cause for the commonly held rule that mismatching datatypes causes performance problems due to "implicit conversions" (since most people are probably not doing additional testing with Windows Collations).
The simple example below illustrates the behavior across the four combinations of mismatching the two datatypes in each of the two Collations.
Setup
For this test we will have a single table with four columns (each one representing one of the four previously mentioned combinations). A single row of data is added simply to avoid having an empty table (and as a result, empty indexes), just in case that would somehow affect if / how the indexes are chosen by the Query Optimizer. As the final comment indicates, please do not forget to enable "Include Actual Execution Plan" if you don't already have it enabled.
-- DROP TABLE #IndexTest;
CREATE TABLE #IndexTest
(
[IndexTestID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[8bit_SqlCollation] VARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Unicode_SqlCollation] NVARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[8bit_WinCollation] VARCHAR(50) COLLATE Latin1_General_100_CI_AS NOT NULL,
[Unicode_WinCollation] NVARCHAR(50) COLLATE Latin1_General_100_CI_AS NOT NULL
);
SET NOCOUNT ON;
INSERT INTO #IndexTest VALUES ('a', N'a', 'a', N'a');
CREATE INDEX [IX_#IndexTest_ASCII_Sql] ON #IndexTest ([8bit_SqlCollation] ASC);
CREATE INDEX [IX_#IndexTest_Unicode_Sql] ON #IndexTest ([Unicode_SqlCollation] ASC);
CREATE INDEX [IX_#IndexTest_ASCII_Win] ON #IndexTest ([8bit_WinCollation] ASC);
CREATE INDEX [IX_#IndexTest_Unicode_Win] ON #IndexTest ([Unicode_WinCollation] ASC);
-- Enable "Include Actual Execution Plan" (Control-M)
Tests
This first test is merely a control to assure us that under "normal" conditions, the system works as expected and each of the indexes is indeed used.
-- First, make sure everything works as expected: SELECT [IndexTestID] FROM #IndexTest WHERE [8bit_SqlCollation] = 'a'; SELECT [IndexTestID] FROM #IndexTest WHERE [Unicode_SqlCollation] = N'a'; SELECT [IndexTestID] FROM #IndexTest WHERE [8bit_WinCollation] = 'a'; SELECT [IndexTestID] FROM #IndexTest WHERE [Unicode_WinCollation] = N'a'; -- Index Seek for all 4 queries

These next two tests show the behavior when using a SQL Server Collation.
-- Next, switch up datatypes on comparisons for SQL Server Collations: SELECT [IndexTestID] FROM #IndexTest WHERE [Unicode_SqlCollation] = 'a'; -- Index Seek SELECT [IndexTestID] FROM #IndexTest WHERE [8bit_SqlCollation] = N'a'; -- Index Scan AND warning on CONVERT_IMPLICIT !!!!

As expected, there's no problem at all with the NVARCHAR column mixed with a non-Unicode value.
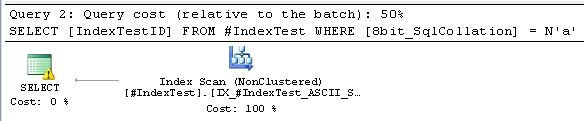
Also expected is the inability of the VARCHAR column to get an Index Seek when mixed with a Unicode value. Not only does that combination get an Index Scan, but it also has a warning on the implicit conversion. Again, the cause of this behavior is the drastically different sorting algorithms: simple ordering for VARCHAR data vs. complex linguistic rules (i.e. Unicode) for NVARCHAR data (changing the datatype changes the sort order).
The final two tests show the behavior when using a Windows Collation.
-- Finally, switch up datatypes on comparisons for Windows Collations: SELECT [IndexTestID] FROM #IndexTest WHERE [Unicode_WinCollation] = 'a'; -- Index Seek SELECT [IndexTestID] FROM #IndexTest WHERE [8bit_WinCollation] = N'a'; -- Index Seek + Nested Loop + Compute Scalar + Constant Scan

As expected, there's no problem at all with the NVARCHAR column mixed with a non-Unicode value ("Query 1" plan shown above).

But, as many would probably not expect, while there's a slight hit to performance due to the implicit conversion (the "Compute Scalar" operator in the "Query 2" plan shown above), it does not get a warning. Also, unlike the VARCHAR column using the SQL Server Collation mixed with a Unicode value, this time, with the Windows Collation, we are back to getting an Index Seek :-). This is due to the Windows Collation using the same linguistic (Unicode) rules for both VARCHAR and NVARCHAR data. Therefore, the VARCHAR values in the index are already in the same order they would be in if converted to NVARCHAR (changing the datatype does not change the sort order).
Conclusion
As shown above, the effect of mixing N[VAR]CHAR and [VAR]CHAR types on the ability to get optimal index usage is entirely dependent on which one of those is indexed and which type of Collation is being used:
- If the indexed column is of type
N[VAR]CHAR, then there are no problems, regardless of which type of Collation is being used (sinceN[VAR]CHARuses Unicode sorting rules in both cases). - If the indexed column is of type
[VAR]CHARand the column is using a Windows Collation, then there is a slight hit to performance for the implicit conversion (of the[VAR]CHARvalue intoN[VAR]CHAR), but you can still get an Index Seek due to the same linguistic sorting and comparison rules being used for both datatypes. - If the indexed column is of type
[VAR]CHARand the column is using a SQL Server Collation, then there is a significant hit to performance for both the implicit conversion (this combination even gets a warning), and getting an Index Scan instead of an Index Seek. This is the only combination to truly suffer from the datatype mismatch, and that's due entirely to different linguistic sorting and comparison rules being used for each datatype.
ALSO, while it is common to hear people warn against “implicit conversions” causing performance problems (at least in terms of mixing VARCHAR and NVARCHAR data), the tests here prove that it’s not the implicit conversion itself that’s the issue. The real issue is the change in sort order resulting from that specific conversion scenario: indexed VARCHAR column using a SQL Server collation. The implicit conversion when using the Windows collation had only minimal impact.
Addendum
- If you are wondering why there's no implicit conversion when comparing the
NVARCHARcolumn to theVARCHARvalue, that's because theVARCHARvalue is converted toNVARCHARbefore the query is actually executed. You can see this if you look at the Execution Plan XML. AVARCHARliteral will automatically be prefixed with an upper-case “N”, while aVARCHARvariable will be wrapped in aCONVERT_IMPLICIT(). - If you are wanting more realistic test data, then just replace the single “
INSERT INTO #IndexTest...” line with the following:INSERT INTO #IndexTest SELECT ac1.[name], ac1.[name], ac1.[name], ac1.[name] FROM master.sys.columns ac1 CROSS JOIN master.sys.columns ac2; -- 1,177,225 rows (on SQL Server 2017, CU 15)and re-run the "Setup" (starting with the “
DROP TABLE #IndexTest;” statement).
Then you can run the following tests. Please note:- Each test is separated with a
GOto put them in separate batches. I've found that having all of them in the same batch affects the execution times (CPU and elapsed) such that what is required by each query depends on its order within the batch. That behavior makes the execution times an unreliable metric. - I use
CONTEXT_INFOso that I can set the test value in one place and use it in multiple batches (since variables do not survive beyond the current batch).
DECLARE @TestValue VARBINARY(128) = CONVERT(VARBINARY(128), 'location'); SET CONTEXT_INFO @TestValue; GO SELECT CONVERT(VARCHAR(50), [context_info]) FROM sys.dm_exec_sessions WHERE [session_id] = @@SPID; GO DECLARE @VC1 VARCHAR(50); SELECT @VC1 = CONVERT(VARCHAR(50), [context_info]) FROM sys.dm_exec_sessions WHERE [session_id] = @@SPID; SET STATISTICS TIME, IO ON; SELECT [IndexTestID] FROM #IndexTest WHERE [Unicode_SqlCollation] = @VC1; SET STATISTICS TIME, IO OFF; -- Index Seek GO PRINT '-----'; DECLARE @NVC1 NVARCHAR(50); SELECT @NVC1 = CONVERT(VARCHAR(50), [context_info]) FROM sys.dm_exec_sessions WHERE [session_id] = @@SPID; SET STATISTICS TIME, IO ON; SELECT [IndexTestID] FROM #IndexTest WHERE [8bit_SqlCollation] = @NVC1; SET STATISTICS TIME, IO OFF; -- Index Scan AND warning on CONVERT_IMPLICIT !!!! GO PRINT '-----'; DECLARE @VC2 VARCHAR(50); SELECT @VC2 = CONVERT(VARCHAR(50), [context_info]) FROM sys.dm_exec_sessions WHERE [session_id] = @@SPID; SET STATISTICS TIME, IO ON; SELECT [IndexTestID] FROM #IndexTest WHERE [Unicode_WinCollation] = @VC2; SET STATISTICS TIME, IO OFF; -- Index Seek GO PRINT '-----'; DECLARE @NVC2 NVARCHAR(50); SELECT @NVC2 = CONVERT(VARCHAR(50), [context_info]) FROM sys.dm_exec_sessions WHERE [session_id] = @@SPID; SET STATISTICS TIME, IO ON; SELECT [IndexTestID] FROM #IndexTest WHERE [8bit_WinCollation] = @NVC2; SET STATISTICS TIME, IO OFF; -- Index Seek + Nested Loop + Compute Scalar + Constant Scan GO
That returns 2170 rows per query with the following stats:
Column Comparison Statistics Datatype Collation type Datatype Time (ms) I/O (logical reads) NVARCHAR SQL Server VARCHAR CPU = 0, elapsed = 1 12 VARCHAR SQL Server NVARCHAR CPU = 235, elapsed = 239 3473 NVARCHAR Windows VARCHAR CPU = 0, elapsed = 1 12 VARCHAR Windows NVARCHAR CPU = 0, elapsed = 2 10 Looking at the results shown above, we can see that the combination of "Indexed
VARCHARcolumn using a Windows collation compared toNVARCHAR" (bottom row in the chart) takes 2 seconds instead of 1 second, which technically is double the original time, but realistically is still barely noticeable. And, interestingly enough, the logical reads are actually down by 2 in that implicit conversion scenario. Unexpected, and in all, I would say that this hardly qualifies as serious performance degradation.HOWEVER, looking at the combination of "Indexed
VARCHARcolumn using a SQL Server collation compared toNVARCHAR" (second row in the chart) is quite obviously slower / less efficient. - Each test is separated with a
- UTF-8 specific behavior: There is no special behavior, as it relates to what is being discussed in this post, when using a UTF-8 collation (new in SQL Server 2019) for the
VARCHARcolumn. Even though theVARCHARcolumn will be able to hold the full range of Unicode characters (as opposed to the much more limited set of characters available in Single-Byte and Double-Byte character sets), the UTF-8 collations are still Windows collations that use the same Unicode sorting and comparison rules for bothVARCHARandNVARCHARdata. In fact, that behavior should be more intuitively obvious in this scenario since theVARCHARdata will actually be Unicode, and therefore expected to already be using Unicode sorting rules.
[…] Solomon Rutzky walks through some of the nuance of mixing VARCHAR and NVARCHAR data types with respe…: […]
[…] characters, supports Supplementary Characters, and is a Windows Collation (hence you don’t prevent seeks on indexed VARCHAR columns when compared to Unicode data). Sure, changing the default Collation after all these years will result in some headaches when […]