


(last updated: 2021-07-30 @ 16:00 EST / 2021-07-30 @ 20:00 UTC )
2021-07-27: This post has just been updated with the results of recent testing on SQL Server 7.0 RTM. The research indicated that support for Double-Byte Character Sets actually started in SQL Server 7.0 instead of SQL Server 2000.This post will be updated again very soon, in conjunction with a new post focusing on UCS-2 vs UTF-16, and including proof that SQL Server 7.0 RTM, released 3 years before the first Supplementary Characters were added to Unicode, stores and retrieves Supplementary Characters without any problems. Please check back soon.😺
Let’s start with a little quiz, shall we?
Question #1: How many licks does it take to get to the Tootsie Roll center of a Tootsie Pop?
Answer #1: If you were thinking “3”, then you are apparently correct (see video below for explanation)
Question #2: How many bytes does a character take up in VARCHAR and NVARCHAR data?
Answer #2: It depends (standard answer, right?). If you were thinking “1” for VARCHAR and “2” for NVARCHAR, then most people would agree with you. However, you would still be incorrect as that answer is (unfortunately) a nearly universal misunderstanding.
For VARCHAR, some of you might be thinking that it was “1” until recently when SQL Server 2019 introduced the "_UTF8" collations. Nope. SQL Server has allowed for 2-byte characters, in VARCHAR, since at least version 7.0 (I don’t have 6.5 or earlier to test with), via Double-Byte Character Sets.
For NVARCHAR, some of you might be thinking that it was “2” until SQL Server 2012 introduced the "_SC" collations that fully support Supplementary Characters (UTF-16). Sorry, still incorrect. “2” was never technically correct for NVARCHAR, it was only temporarily correct for the first few years (until the first Supplementary Characters were defined in Unicode 3.1, published in March, 2001). Ever since SQL Server 7.0 introduced the NCHAR, NVARCHAR, and NTEXT datatypes, it has been possible to store whatever UTF-16 byte sequences you want, even if they are currently undefined. The older collations do not recognize surrogate pairs / Supplementary Characters for string operations, but that’s not related to SQL Server’s ability to store and retrieve any 16-bit code unit. As long as you are using a font that supports Supplementary Characters, they will display correctly.
What is a “Character”?
Here we are not talking about multi-character text elements / glyphs, such as:
- Combining character sequences: Hebrew Letter Shin (U+05E9) + Sin dot (above / left; U+05C2) + vowel (below; U+05B8) + cantillation mark (above / right; U+05A8) (four BMP code points)
SELECT NCHAR(0x05E9) + NCHAR(0x05C2) + NCHAR(0x05B8) + NCHAR(0x05A8);
Returns (it might not look the same in the grid, but copy and paste into a browser):
שָׂ֨
-
Complex Emojis:
"Keycap: *" (three BMP code points):
SELECT NCHAR(0x002A) + NCHAR(0xFE0F) + NCHAR(0x20E3);
Returns (it might not look the same in the grid, but copy and paste into a browser):
*️⃣
OR, “Family: man, woman, girl, boy” (combination of three BMP and four Supplementary code points):
(U+1F468) + (U+200D) + (U+1F469) + (U+200D) + (U+1F467) + (U+200D) + (U+1F466)SELECT NCHAR(0xD83D) + NCHAR(0xDC68) + NCHAR(0x200D) + NCHAR(0xD83D) + NCHAR(0xDC69) + NCHAR(0x200D) + NCHAR(0xD83D) + NCHAR(0xDC67) + NCHAR(0x200D) + NCHAR(0xD83D) + NCHAR(0xDC66);Returns (it might not look the same in the grid, but copy and paste into a browser):
👨👩👧👦
When we talk about “characters”, we are talking about individual code points, regardless of how they appear, or even if they aren’t visible.
VARCHAR / CHAR and NVARCHAR / NCHAR
There is some complexity to this section so please forgive the length of it. Eventually, the Supplementary Character info will be moved into its own post with even more details and queries, etc.
NVARCHAR / NCHAR (starting in SQL Server 7.0, released in 1998)
NCHAR and NVARCHAR are 16-bit datatypes. The character set is always Unicode, and the encoding used to store characters is always UTF-16 (UTF-16 Little Endian to be precise; more on that in a moment). UTF-16 is a variable-width encoding that uses one or two 16-bit (i.e. two-byte) “code units” to represent each character. Unicode is capable of mapping up to 1,114,112 characters (well, that many code points / values, some of which will never be actual characters). The characters are loosely grouped into 17 “planes” of 64k (65,536) code points each. The first plane is the Basic Multilingual Plane (BMP) and includes code points U+0000 through U+FFFF. The remaining characters, code points U+10000 through U+10FFFF, are in the supplementary planes and are known as Supplementary Characters.
The BMP range is fairly straight forward, but Supplementary Characters are where things start to get confusing. Initially there was only the BMP range and the UCS-2 encoding (which is a fixed-width, 16-bit encoding in which only a single two-byte “code unit” is used for each character, and includes all BMP code points). In UCS-2, “code points” and “code units” are effectively the same thing. There are 2048 code points that are reserved for future use, known as surrogate code points, but otherwise have no meaning or definition.
UTF-16 is effectively no different than UCS-2 except it includes the ability to map and encode the Supplementary Characters. And, it uses those 2048 reserved code points — the high and low surrogate ranges, code points U+D800 through U+DFFF — in combinations called “surrogate pairs” to encode all of the supplementary (i.e. non-BMP) code points / characters.
Microsoft adopted Unicode fairly early on (in Windows NT 3.1 in 1993), prior to UTF-16 being created. When UTF-16 was introduced in Unicode version 2.0, published in 1996, guidance was to use UCS-2, or “Unicode” encoding, unless using “surrogate pairs” (i.e. Supplementary Characters), yet none of those existed (outside of the “private use” range) until 2001. This is not only why the documentation mentions UCS-2 instead of UTF-16 (mostly, but especially for SQL Server 7.0 and 2000, which were both released prior to the first Supplementary Characters being defined), but also why the built-in functions handle strings as UCS-2 (typically, more on this below) instead of as UTF-16 (meaning: they see surrogate pairs as two unassigned characters instead of a single character).
Implications of UCS-2 and UTF-16 using the same 16-bit units
(note: this section will soon be moved to an independent post where it will be expanded with more details, history, and proof that SQL Server 7.0 and Query Analyzer can store, retrieve, and display supplementary characters.)
Because both UCS-2 and UTF-16 use the same 16-bit “code units”, they are identical from a storage perspective. Meaning, there is no difference between storing UCS-2 and storing UTF-16. This is why SQL Server was able to store UTF-16 data back in version 7.0, which was: two years before UTF-16 even existed, three years before any Supplementary Characters were defined, and at least three (maybe four?) years before any of those Supplementary Characters were supported in any fonts (i.e. were usable). I have tested on SQL Server 7.0 and it does indeed store, retrieve, and display Supplementary Characters (though displaying those characters is the responsibility of the font and UI).
Also, because those 2048 surrogate code points are used in UTF-16 to encode Supplementary Characters yet are undefined in UCS-2, UCS-2 data works just fine in software that supports both of those encodings, but UTF-16 data might contain surrogate pairs that are considered invalid in software that only supports UCS-2. For software that only supports UCS-2, depending on how the data is processed, it might appear as two default replacement characters — �� — or it might display correctly but not otherwise work correctly. For example, in SQL Server, the version 80 collations (i.e. the ones that came with SQL Server 2000, both Windows and SQL Server collations) do not have any sort weights for the surrogate code points. This means that those code points, whether used in valid surrogate pairs to represent Supplementary Characters, or in any invalid combination, are completely invisible in terms of sorting any comparison (unless using a binary collation). And, even a valid surrogate pair will be seen as two separate code points, rather than a single supplemental code point, to built-in functions.
UTF-16 support and "_SC" collations
Starting in SQL Server 2005, Microsoft has been slowly transitioning from a UCS-2 approach to UTF-16, in terms of actually working with the data, not just viewing it.
- SQL Server 2005: Microsoft added the ability to work with Supplementary Characters at a very basic level starting with the version 90 collations (i.e. those introduced in SQL Server 2005). Instead of Supplementary Characters being effectively invisible to sorting and filtering operations, they now all registered as being unique code points. In order to accomplish this without implementing full support for UTF-16, Microsoft "cheated" a little by adding sort weights to 256 of the “high” surrogate code points and to all 1024 “low” surrogate code points (I say "cheated" because in true Unicode, these code points should not have any sort weights). Adding sort weights to surrogate code points does not magically allow SQL Server to recognize valid surrogate pairs as being a single Supplementary Character; surrogate pairs are still seen as two separate characters by all built-in functions. However, the end result is still a major improvement in that Supplementary Characters can at least be distinguished from each other (and from all other characters). All Supplementary Characters sort according to their code point value.
- SQL Server 2008: Some collations that were introduced in this version (i.e. the version 100 collations) were enhanced in their support of Supplementary Characters. Specifically, tens of thousands of Chinese Supplementary Characters were given a proper, linguistic ordering in the various Chinese collations (and only the Chinese collations, regardless of the official documentation incorrectly stating that all version 100 collations supporting linguistic ordering).
- SQL Server 2012: This version duplicated many (or all?) of the collations that were introduced in both SQL Server 2005 (i.e. the version 90 collations) and SQL Server 2008 (i.e. the version 100 collations) to add the "
_SC" flag. The “SC” stands for “S”upplementary “C”haracter support. This option enables full UTF-16 support, which really only means that the built-in functions (e.g.LEN(),SUBSTRING(), etc) can finally see Supplementary Characters as individual entities instead of being two surrogate code points. (see examples below) - SQL Server 2017: This version came with new Japanese collations, and in doing so, introduced two new concepts, one obvious, and other more subtle. The “obvious” change is the introduction of the Variation-Selector Sensitive option (“
_VSS“). The “subtle” change is that none of these version 140 collations have the "_SC" flag in their names. The flag isn’t necessary for new (i.e. version 140 and newer) collations as Supplementary Character / full UTF-16 support is assumed (woo hoo!).
Examples
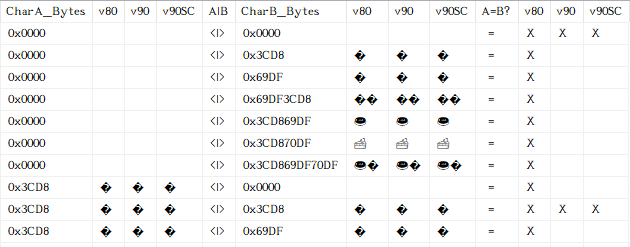
The following example shows that:
- In the version 80 collations (both SQL Server collations and Windows collations), all surrogate code points (and thus, all Supplementary Characters) equate to each other as well as equating to the “null” character (U+0000). This is due to none of them having any sort weights defined.
- Starting with version 90 collations, surrogate code points (at least some of them) only equate to themselves. This explains how it is that:
- Supplementary Characters only equate to themselves.
- invalid (i.e. incomplete) surrogate pairs still equate to themselves.
- Using a Supplementary Character-Aware collation did not affect sorting and filtering.
;WITH chr AS
(
SELECT tmp.[col] AS [Surrogate]
FROM (VALUES
(CONVERT(NVARCHAR(30), NCHAR(0))), -- null
(NCHAR(0xD83C)), -- Surrogate code points / invalid when used
(NCHAR(0xDF69)), -- individually / valid only in pairs & only in UTF-16
(NCHAR(0xDF69) + NCHAR(0xD83C)), -- Invalid pair (incorrect order)
(NCHAR(0xD83C) + NCHAR(0xDF69)), -- Valid pair (only used in UTF-16)
(NCHAR(0xD83C) + NCHAR(0xDF70)), -- Valid pair (only used in UTF-16)
(NCHAR(0xD83C) + NCHAR(0xDF69) + NCHAR(0xDF70)) -- Valid pair + invalid
) tmp(col)
)
SELECT CONVERT(VARBINARY(30), chrA.[Surrogate]) AS [CharA_Bytes],
chrA.[Surrogate] COLLATE Japanese_CS_AS_KS_WS AS [v80],
chrA.[Surrogate] COLLATE Japanese_90_CS_AS_KS_WS AS [v90],
chrA.[Surrogate] COLLATE Japanese_90_CS_AS_KS_WS_SC AS [v90SC],
'<|>' AS [A|B],
CONVERT(VARBINARY(30), chrB.[Surrogate]) AS [CharB_Bytes],
chrB.[Surrogate] COLLATE Japanese_CS_AS_KS_WS AS [v80],
chrB.[Surrogate] COLLATE Japanese_90_CS_AS_KS_WS AS [v90],
chrB.[Surrogate] COLLATE Japanese_90_CS_AS_KS_WS_SC AS [v90SC],
' =' AS [A=B?],
CASE WHEN chrA.[Surrogate] = chrB.[Surrogate]
COLLATE Japanese_CS_AS_KS_WS
THEN 'X'
ELSE ''
END AS [v80],
CASE WHEN chrA.[Surrogate] = chrB.[Surrogate]
COLLATE Japanese_90_CS_AS_KS_WS
THEN 'X'
ELSE ''
END AS [v90],
CASE WHEN chrA.[Surrogate] = chrB.[Surrogate]
COLLATE Japanese_90_CS_AS_KS_WS_SC
THEN 'X'
ELSE ''
END AS [v90SC]
FROM chr chrA
CROSS JOIN chr chrB;
The following results are from the query shown directly above:
The following example shows how a BMP character and a Supplementary Character are handled by a few different built-in functions:
;WITH src(item) AS
(
SELECT CONVERT(NVARCHAR(2), NCHAR(0x0496)) -- Cyrillic Capital Letter Zhe
UNION ALL
SELECT NCHAR(0xD83C) + NCHAR(0xDF69) -- Doughnut (U+1F369)
), chr AS
(
SELECT src.[item] COLLATE Latin1_General_100_CI_AS AS [Non-"_SC"],
src.[item] COLLATE Latin1_General_100_CI_AS_SC AS ["_SC"]
FROM src
)
SELECT chr.[Non-"_SC"] AS [Non-"_SC"],
DATALENGTH(chr.[Non-"_SC"]) AS [Non-"_SC" Byte Count],
LEN(chr.[Non-"_SC"]) AS [Non-"_SC" Character Count],
SUBSTRING(chr.[Non-"_SC"], 1, 1) AS [Non-"_SC" Substring],
'--' AS [---],
chr.["_SC"] AS ["_SC"],
DATALENGTH(chr.["_SC"]) AS ["_SC" Byte Count],
LEN(chr.["_SC"]) AS ["_SC" Character Count],
SUBSTRING(chr.["_SC"], 1, 1) AS ["_SC" Substring]
FROM chr;
returns:
Non-"_SC" | Non-"_SC" | Non-"_SC" | Non-"_SC" Character | Byte Count | Character Count | Substring Җ | 2 | 1 | Җ 🍩 | 4 | 2 | � ____________________________________________________________ "_SC" | "_SC" | "_SC" | "_SC" Character | Byte Count | Character Count | Substring Җ | 2 | 1 | Җ 🍩 | 4 | 1 | 🍩
As you can see in the results shown above:
- The BMP character is the same in both "
_SC" and non-"_SC" collations: it’s 2 bytes, 1 character, and theSUBSTRING()operation works just fine. - The Supplementary Character is not the same between the "
_SC" and non-"_SC" collations. While it does correctly report being 4 bytes in both cases, theLEN()andSUBSTRING()functions:- work correctly in the "
_SC" collation because it handles the data as UTF-16 which handles surrogate pairs as individual supplementary code points. - are only able to see surrogate code points, even if used in valid surrogate pair combinations.
- work correctly in the "
Additional Notes and Summary
- Another feature of "
_SC" collations:The
NCHAR()function is also affected by the type of collation used. But, unlike the other functions, the behavior only occurs if the current database’s default collation is Supplementary Character-Aware (SCA; i.e. has "_SC", or "_140_" but not "_BIN*", in the name). In a database with a non-SCA default collation, theNCHAR()function returnsNULLif given a value greater than 65535 (0xFFFF). However, in a database with an SCA default collation, theNCHAR()function returns the corresponding Supplementary Character (or surrogate pair, if you prefer to look at it that way) if given a value between 65536 (0x10000) and 1114111 (0x10FFFF).SELECT NCHAR(0x1F369); -- NULL (in DB with non-SCA default collation, or even -- Latin1_General_100_BIN2_UTF8 or Japanese_XJIS_140_BIN2) -- 🍩 (in DB with Supplementary Character-Aware default collation)Please support (i.e. vote for) my suggestion: “NCHAR() function should always return Supplementary Character for values 0x10000 – 0x10FFFF regardless of active database’s default collation”.
-
Endianness:
The order in which bytes of multi-byte entities are stored is system dependent. This ordering is called “endianness”. If the bytes are stored in their natural order (i.e. bytes ordered from first to last), that is called “Big Endian”. Or, if the bytes are stored in reverse order (i.e. bytes ordered from last to first), that is called “Little Endian”. For example, if we have 3 bytes —
0xAB,0xCD, and0xEF— then “Big Endian” would be0xABCDEF, while “Little Endian” would be0xEFCDAB. Windows is a Little Endian system, and thus so is .NET, SQL Server, etc.- The 16-bit datatypes (which includes
NTEXT, discussed below), not too surprisingly, store each character as 16-bit units. This is why, in a Little Endian system, the UTF-16 code unit of0x12ABis actually stored as0xAB12. This is also why the surrogate pair0xD801,0xDC02is actually stored as0x01D802DCsince the two 16-bit units (each of which have their bytes stored in reverse order) are stored in their natural order, instead of all four bytes being stored as0x02DC01D8(or something like that). - This does not affect UTF-8 (discussed below) code points stored as 2, 3, or 4 bytes. This is due to those multi-byte combinations not being a single unit, but a series of 1-byte units whose combination is associated with a specific Unicode code point. This is no different than UTF-16 using surrogate pairs for Supplementary Characters. The surrogate pair is still two 2-byte units, and those same characters in UTF-8 are four 1-byte units. Neither case is handled as a single 4-byte unit.
- This also does not affect Double-Byte Character Set (discussed below) characters stored as 2 bytes. The reason is the same as for UTF-8 (noted directly above): they are just two 1-byte unit combinations.
- The 16-bit datatypes (which includes
BYTES PER CHARACTER: 2 or 4
VARCHAR / CHAR
CHAR and VARCHAR are 8-bit datatypes. The character set / encoding used to store characters depends on the collation being used (which depends on the context of the usage: data in a column uses the column’s collation; variable and string literals use the current database’s default collation). Most collations (except for a small number of Unicode-only collations) have an associated code page. That code page is the character set used for this data. For example, all "SQL_Latin1_General_CP1_*" and "Latin1_General_*" collations use code page Windows-1252.
Single-Byte Character Sets
Single-Byte Character Sets (SBCS) always use 1 byte per character, and can map up to 256 characters (some code points in some code pages are undefined). Most of the code pages available in SQL Server are of this single-byte variety. Some examples include: Windows-1252 (Latin1_General / Western European) and Windows-1255 (Hebrew). For the code pages supported by SQL Server, the first 128 characters (code points 0 – 127 / 0x00 – 0x7F) are the same. But, any of the code points 128 – 255 / 0x80 – 0xFF, can be different between the code pages, and many are (this is, after all, the reason for their being code pages in the first place).
DECLARE @VarChar TABLE
(
[Latin1_General] CHAR(1) COLLATE Latin1_General_100_CI_AS NOT NULL,
[Hebrew] CHAR(1) COLLATE Hebrew_100_CI_AS NOT NULL,
[Turkmen] CHAR(1) COLLATE Turkmen_100_CI_AS NOT NULL
);
DECLARE @Standard BINARY(1) = 0x41,
@Extended BINARY(1) = 0xE0;
INSERT INTO @VarChar VALUES (@Standard, @Standard, @Standard);
INSERT INTO @VarChar VALUES (@Extended, @Extended, @Extended);
SELECT *
FROM @VarChar;
/*
Latin1_General Hebrew Turkmen
A A A
à א ŕ
*/
As you can see above, in the results below the query, code point 0x41, being between 0x00 and 0x7F, is the same across all 3 code pages. Code point 0xE0 is different across all three. And each character is just one byte (that’s all there is room for, anyway).
BYTES PER CHARACTER: 1
Double-Byte Character Sets (starting in SQL Server 7.0, released in 1998)
Double-Byte Character Sets (DBCS) use either 1 or 2 bytes per character, and can map up to approximately 24,196 characters (some code points in some code pages are undefined). There are four DBCS code pages available in SQL Server: Windows-932 (Japanese), Windows-936 (Chinese {PRC & Simplified}), Windows-949 (Korean), and Windows-950 (Chinese {Taiwan & Traditional & Hong_Kong}). These code pages are only available in Windows collations (i.e. collation names not starting with "SQL_"), not in the SQL Server collations (i.e. collation names starting with "SQL_"). In SQL Server 7.0, which did not have named collations, those four DBCS options were available in the code page / locale drop-down when selecting the collation for VARCHAR data during SQL Server installation.
Double-Byte Character Sets are variable-width encodings. The first 128 bytes (0x00 – 0x7F) are all individual characters, plus 0x80 and 0xFF, are either individual characters or undefined. But, bytes 0x81 – 0xFE are considered “Lead Bytes” that are always followed by a “Trail Byte”. Trail Bytes can be in the range of 0x40 – 0xFE. These two-byte combinations allow for going beyond the 256 mappings that are possible in Single-Byte Character Sets. There is additional complexity, though, since the range of Trail Byte values overlaps with half of the single-byte range and all of the Lead Byte range.
DECLARE @Character NVARCHAR(10) = NCHAR(0xC3B5); -- U+C3B5
;WITH chr AS
(
SELECT @Character AS [UTF-16],
CONVERT(VARCHAR(50), @Character
COLLATE Latin1_General_100_CI_AS) AS [Windows-1252],
CONVERT(VARCHAR(50), @Character
COLLATE Korean_100_CI_AS) AS [Windows-949]
)
SELECT chr.[Windows-1252],
'--' AS [---],
chr.[UTF-16],
CONVERT(VARBINARY(10), chr.[UTF-16]) AS [UTF-16 Bytes],
'--' AS [---],
chr.[Windows-949],
CONVERT(VARBINARY(10), chr.[Windows-949]) AS [Windows-949 Bytes]
FROM chr;
GO
/*
Windows-1252: ?
---
UTF-16: 쎵
UTF-16 Bytes: 0xB5C3
---
Windows-949: 쎵
Windows-949 Bytes: 0x9BDC
*/
As you can see above, in the results shown in the comment block after the query, the character that is Unicode code point U+C3B5, is converted to two different 8-bit code pages. The character does not exist in the single-byte Windows-1252 (hence the "?"), but it does exist in the double-byte Windows-949 code page. And, not only does that character exist in the Korean code page, but it is now two bytes: 0x9B (the Lead Byte), followed by 0xDC (the Trail Byte).
Please note that since Double-Byte Character Sets are still 8-bit, there is no concept of Endianness: the Lead Byte is always first, and the Trail Byte is always second.
BYTES PER CHARACTER: 1 or 2
UTF-8 (starting in SQL Server 2019)
UTF-8 is a variable-width Unicode encoding. It uses between 1 and 4 bytes per code point / character, depending on what range the code point is in. BMP characters use 1 to 3 bytes, and Supplementary Characters use 4 bytes in all Unicode encodings. The primary goal for UTF-8 was to allow for full ASCII compatibility such that systems designed for 8-bit ASCII could become Unicode compatible without altering the interpretation of (i.e. breaking) any existing files. This allowed systems (primarily UNIX) to slip in support for Unicode without breaking existing processes.
UTF-8 is now the standard / most common encoding used on the Internet, due to both the ASCII compatibility feature as well as the potentially reduced size when compared to UTF-16 (assuming a desire or requirement to store Unicode data). The space savings is only potential because it’s only the first 128 code points (i.e. the standard ASCII character set: US English alphabet, digits 0 – 9, and some punctuation) that offer any space savings. This is an advantage for documents that are mostly standard ASCII characters. Because of this, there’s an unfortunately common misunderstanding among those who usually only deal with standard ASCII characters that UTF-8 "saves space". However, UTF-8 is actually worse for documents in which at least 50% of the characters are in the 0x0800 through 0xFFFF range (i.e. most of the BMP code points). AND, UTF-8 is often less efficient for processing than UTF-16.
The chart below shows which code points take up each quantity of bytes:
| Code Points | Code Point Quantity |
UTF-8 Size (bytes) |
UTF-16 Size (bytes) |
UTF-8 savings |
|---|---|---|---|---|
| 0 – 127 | 128 | 1 | 2 | 1 |
| 127 – 2047 | 1920 | 2 | 2 | 0 |
| 2048 – 65535 | 63488 | 3 | 2 | -1 |
| 65536 – 1114111 | 1048576 | 4 | 4 | 0 |
Below we have an example showing characters of each of the four byte sizes. The fourth character — the one created from the surrogate pair — is code point U+1040F. The empty string literal is only there to set the datatype of the "[chr]" column of the derived table (i.e. "tmp") to NVARCHAR, else it would be NCHAR(2) which would include an extraneous space (i.e. code point 0x20) in the first three characters.
SELECT CONVERT(VARCHAR(10), tmp.[chr]
COLLATE Latin1_General_100_CI_AS_SC_UTF8) AS [UTF-8],
CONVERT(VARBINARY(10), CONVERT(VARCHAR(10), tmp.[chr]
COLLATE Latin1_General_100_CI_AS_SC_UTF8)) AS [UTF-8 Bytes]
FROM (VALUES
(NCHAR(0x0041)), -- Latin Capital Letter A
(NCHAR(0x0496)), -- Cyrillic Capital Letter Zhe
(NCHAR(0xC3B5)), -- Hangul Syllable Ssyeong
(NCHAR(0xD801) + NCHAR(0xDC0F)), -- Deseret Capital Letter Yee
(CONVERT(NVARCHAR(5), '')) -- else datatype is NCHAR(2)
) tmp(chr)
WHERE DATALENGTH(tmp.[chr]) > 0;
which returns:
UTF-8 | UTF-8 Bytes A | 0x41 Җ | 0xD296 쎵 | 0xEC8EB5 𐐏 | 0xF090908F
The UTF-8 collations all have names ending with "_UTF8". Prior to SQL Server 2019, the VARCHAR datatype was “non-Unicode”. That description no longer applies. So, as of SQL Server 2019, VARCHAR is just an “8-bit” datatype.
Please note that since UTF-8 is still an 8-bit encoding, there is no concept of Endianness: Bytes 2, 3, and 4, when present, are always in their natural order.
For more details on UTF-8 support in SQL Server, please see: “Native UTF-8 Support in SQL Server 2019: Savior or False Prophet?”.
BYTES PER CHARACTER: 1, 2, 3, or 4
VARCHAR Summary
BYTES PER CHARACTER:
- pre-SQL Server 7.0: 1
- SQL Server 7.0 through SQL Server 2017: 1 or 2
- as of SQL Server 2019: 1, 2, 3, or 4
TEXT and NTEXT
The TEXT and NTEXT datatypes have been deprecated since the release of SQL Server 2005 and should not be used (unless you are working with legacy code and cannot avoid these types). You should instead use VARCHAR(MAX) and NVARCHAR(MAX), respectively. I am only including them in this post for the sake of completeness because they have not been removed from SQL Server so there is still a chance that you might encounter them, hence it’s best to understand their behavior.
TEXT
To test the TEXT datatype, we will create an NVARCHAR character since we can do that reliably without concern for the default collation of the current database. We will then convert it to a Single-Byte Character Set (Windows-1252), and to a Double-Byte Character Set (Windows-949). We are converting to VARCHAR first so that we know it works before attempting to convert it to TEXT.
DECLARE @Character NVARCHAR(10) = NCHAR(0xC3B5); -- U+C3B5
;WITH chr AS
(
SELECT @Character AS [UTF-16],
CONVERT(VARCHAR(50), @Character
COLLATE Latin1_General_100_CI_AS) AS [Windows-1252],
CONVERT(VARCHAR(50), @Character
COLLATE Korean_100_CI_AS) AS [Windows-949]
)
SELECT chr.[Windows-1252],
'--' AS [---],
chr.[UTF-16],
CONVERT(VARBINARY(10), chr.[UTF-16]) AS [UTF-16 Bytes],
'--' AS [---],
chr.[Windows-949],
CONVERT(VARBINARY(10), chr.[Windows-949]) AS [Windows-949 Bytes],
'--' AS [---],
CONVERT(TEXT, chr.[Windows-949]) AS [Windows-949 as TEXT],
DATALENGTH(CONVERT(TEXT, chr.[Windows-949]))
AS [Windows-949 as TEXT Byte Count]
FROM chr;
GO
/*
Windows-1252: ?
---
UTF-16: 쎵
UTF-16 Bytes: 0xB5C3
---
Windows-949: 쎵
Windows-949 Bytes: 0x9BDC
---
Windows-949 as TEXT: 쎵
Windows-949 as TEXT Byte Count: 2
*/
As you can see above, in the results shown in the comment block after the query, the TEXT datatype has no problem with double-byte characters in code page Windows-949 (a DBCS). Of course, TEXT does not allow for converting to VARBINARY, so we can’t see the exact bytes, but we can at least see that there are 2 bytes, same as with VARCHAR.
Starting in SQL Server 2019, a new series of collations was added to support the UTF-8 encoding. UTF-8 is Unicode’s 8-bit encoding, so it should work with any 8-bit datatype, right? Let’s find out.
-- UTF-8 via VARCHAR:
SELECT CONVERT(VARCHAR(10), NCHAR(0xC3B5)
COLLATE Latin1_General_100_CI_AS_SC_UTF8) AS [UTF-8],
CONVERT(VARBINARY(10), CONVERT(VARCHAR(10), NCHAR(0xC3B5)
COLLATE Latin1_General_100_CI_AS_SC_UTF8)) AS [UTF-8 Bytes];
/*
UTF-8 UTF-8 Bytes
쎵 0xEC8EB5
*/
-- UTF-8 via TEXT:
SELECT CONVERT(TEXT, NCHAR(0xC3B5)
COLLATE Latin1_General_100_CI_AS_SC_UTF8) AS [UTF-8],
DATALENGTH(CONVERT(TEXT, NCHAR(0xC3B5)
COLLATE Latin1_General_100_CI_AS_SC_UTF8)) AS [UTF-8 Byte Count];
/*
Msg 4189, Level 16, State 0, Line XXXXX
Cannot convert to text/ntext or collate to
'Latin1_General_100_CI_AS_SC_UTF8' because these legacy LOB types do not
support UTF-8 or UTF-16 encodings. Use types varchar(max), nvarchar(max)
or a collation which does not have the _SC or _UTF8 flags.
*/
In the example code shown above, the second query fails, stating that you cannot use a UTF-8 collation with the TEXT or NTEXT datatypes (please note that the final part of the error message is incomplete as it should include "_140_" in the list of flags to avoid when using the legacy LOB types).
BYTES PER CHARACTER: 1 or 2
NTEXT (starting in SQL Server 7.0)
NTEXT, like NVARCHAR / NCHAR, is a Unicode-only datatype that always uses the UTF-16 (Little Endian) encoding.
;WITH chr AS
(
SELECT CONVERT(NTEXT, NCHAR(0x2623)
COLLATE Latin1_General_100_CI_AS) AS [Biohazard],
CONVERT(NTEXT, NCHAR(0xD83C) + NCHAR(0xDF69)
COLLATE Latin1_General_100_CI_AS) AS [Doughnut]
)
SELECT chr.[Biohazard],
DATALENGTH(chr.[Biohazard]) AS [Biohazard Byte Count],
chr.[Doughnut],
DATALENGTH(chr.[Doughnut]) AS [Doughnut Byte Count]
FROM chr;
which returns:
Biohazard | Biohazard Byte Count | Doughnut | Doughnut Byte Count ☣ | 2 | 🍩 | 4
As you can see above, in the results shown in the comment block after the query, the NTEXT datatype has no problem storing Supplementary Characters, even though the collation does not specifically support Supplementary Characters. And in fact, as we saw at the end of the TEXT tests, it isn’t even possible for NTEXT to use an "_SC" collation. Still, it makes sense that NTEXT can store Supplementary Characters because it’s just a series of bytes, and the "_SC" collations only affect how certain operations / functions handle these bytes sequences, not how they are stored.
BYTES PER CHARACTER: 2 or 4
XML (starting in SQL Server 2005)
The XML datatype, despite having the appearance of storing a string value, does not store the value as a string, similar to DATETIME not being a string even though you pass in a string to set its value. The XML datatype is optimized to remove non-essential whitespace, and only store unique element and attribute names. Element and attribute names, as well as string values / content are stored using the UTF-16 Little Endian encoding. Typed XML has the optional ability to store non-string values / content in their native format, otherwise all values / content are stored as strings using the UTF-16 Little Endian encoding. The concept of collation does not apply to XML data.
DECLARE @XML XML = N'
<Top>
<LevelB Attrib="AA">
<Level42 Attrib="A1A">AA11</Level42>
<Level42 Attrib="A2A">AA22</Level42>
<Level42 Attrib="A3A">AA33</Level42>
</LevelB>
<LevelB Attrib="BB">
<Level42 Attrib="B1B">BB11</Level42>
<Level42 Attrib="B2B">BB22</Level42>
<Level42 Attrib="B3B">BB33</Level42>
</LevelB>
<LevelB Attrib="Y' + NCHAR(0xC3B5) + N'Y">
<Level42 Attrib="C1C">Y' + NCHAR(0xC3B5) + N'Y</Level42>
</LevelB>
</Top>
';
SELECT @XML AS [XmlValue];
SELECT LEN(CONVERT(NVARCHAR(MAX), @XML)) AS [CharacterCount],
DATALENGTH(CONVERT(NVARCHAR(MAX), @XML)) AS [NVarCharByteCount],
DATALENGTH(@XML) AS [XmlByteCount];
-- CharacterCount NVarCharByteCount XmlByteCount
-- 350 700 280
As you can see above, in the results shown in the comment block after the query, the size of the XML document, when stored in an XML column or variable, is less than half of what it would be if stored as NVARCHAR (even less than the number of characters in the document). This is due to “Top” being stored once instead of 2 times; “LevelB” being stored once instead of 6 times; “Level42” being stored once instead of 14 times; “Attrib” being stored once instead of 10 times; and newlines / CRLFs and extra spaces being removed.
BYTES PER CHARACTER: n/a
Summary
Putting all of the relevant info together in one place, we get the following:
| Datatype | Encoding | Minimum SQL Server Version |
Bytes per Character |
|---|---|---|---|
CHAR /VARCHAR |
Single-Byte Character Set 1 |
<= 6.5 | 1 |
| Double-Byte Character Set 2 |
7.0 | 1 or 2 | |
| UTF-8 3 | 2019 | 1, 2, 3, or 4 | |
NCHAR /NVARCHAR |
UTF-16 | 7.0 | 2 or 4 |
TEXT(deprecated) |
Single-Byte Character Set 1 |
<= 6.5 | 1 |
| Double-Byte Character Set 2 |
7.0 | 1 or 2 | |
NTEXT(deprecated) |
UTF-16 | 7.0 | 2 or 4 |
XML |
UTF-16 | 2005 | n/a |
1: Available Windows Code Pages for Single-Byte Character Sets: 437, 850, 874, 1250, 1251, 1252, 1253, 1254, 1255, 1256, 1257, and 1258.
2: Available Windows Code Pages for Double-Byte Character Sets: 932, 936, 949, and 950.
3: Windows Code Page for UTF-8: 65001.
No one will ever accuse you of not being detailed enough, Solomon. Nice post!
[…] Solomon Rutzky explains that just because you’ve got a VARCHAR column, it’s not necessar…: […]
[…] How Many Bytes Per Character in SQL Server: a Completely Complete Guide […]
[…] Also see: * Please vote for my suggestion to improve the NCHAR() function so that it always supports Supplementary Characters, regardless of the database’s default collation: NCHAR() function should always return Supplementary Character for values 0x1000 – 0x10FFFF regardless of active database’s default collation * How Many Bytes Per Character in SQL Server: a Completely Complete Guide […]
[…] How Many Bytes Per Character in SQL Server: a Completely Complete Guide […]
[…] A very detailed guide on the characters and the whole encoding can be found here. […]
[…] bytes, whereas equivalent VARCHAR characters are typically 1 byte. For the nuanced version of this, Solomon Rutzky goes into great detail on the topic, but let’s stick with the simplistic version for now because I don’t think the added […]
[…] while researching another topic, I came across the following SQL Server 7.0 documentation (published in […]
Thank you ! I found a solution to a text datatype column substring issue with help from your post.